Bin packing strategies for union mounts
Recently I’ve been configuring an old desktop as a NAS/media centre. I settled on using a “JBOD plus redundancy” system like Unraid or SnapRAID+mergerfs for the flexibility that it provides, as opposed to something more enterprise like FreeNAS/ZFS or a traditional RAID setup.
I intend to write a more thorough comparison of these two solutions in the future, but the short summary relevant to this article is that they use plain old filesystems like XFS on each disk and mount them independently, then provide a writeable union mount view. This isn’t as performant as “real” RAID, but for the scenario of media storage that’s usually not an issue, and in fact has the advantage of only spinning one disk at a time.
Creating a read-only union mount is simple enough, but when you add writeability into the equation you have to decide on a strategy to select a drive to write new files to. In theory this shouldn’t matter, but in practice I want to colocate whole TV shows onto one drive, so that a data loss scenario does not result in me having half of 10 shows rather than 5 complete and 5 completely missing shows. I also wanted to write some code and draw some pretty graphs.
Each solution offers a different unique feature that can help with this. Unraid has a “maximum split level”. For example if your schema is share root/TV/Show Name/Season 1/episode.mkv, then you could set the maximum split to two to colocate entire series, or three to colocate only seasons. Mergerfs includes “most-shared path” variants of most strategies, which will try to put new files in an existing directory on the same drive, then move up a level and try again if they won’t fit.
When using SnapRAID, one potential issue with strategies that fill disks unevenly is increasing the likelihood of wasted parity space. See this post, CTRL+F “fragmentation”.
In either case, the raw storage devices are exposed too, so you can always manually manage where things are put. Unraid comes with a web interface to show you where files are allocated, and the third-party “Unbalance” plugin makes it easy to relocate them. Mergerfs is a little more manual. I execute this script that I wrote in the root of the TV shows directory, and then manually use Midnight Commander to move things. I’m planning to work on a more automated solution.
Bin packing
The problem of selecting a bin (drive) to put an item (file) in is known as the bin-packing problem; specifically, the online variant, meaning we don’t have foresight of the files that will come in the future and we’d rather not move them once allocated.
The formal problem described in that article assumes all bins are the same size, which is not the case with my setup. It also considers items of radically different sizes and tries to optimise for the maximum total storage. This is not something I’m concerned with, since the drive are usually so much bigger than the files, and you’re ideally leaving them at <90% usage, so efficiency differences should be negligible.
The strategies are known by different names, so here’s a terminology table. Remember that lus and mfs are equivalent if all bins are the same size.
| Name on Wikipedia | Name in Unraid | Name in mergerfs |
|---|---|---|
| First-Fit? | Fill-up | ff (first found) |
| - | High-water | - |
| Best-Fit? | - | lfs (least free space) |
| Worst-Fit? | - | lus (least used space) |
| Worst-Fit? | Most-free | mfs (most free space) |
| - | - | pfrd (percentage free random distribution) |
| - | - | rand (random) |
I wrote a little utility to simulate the different strategies of Unraid and mergerfs. Its main flaw is that it does not test the path-preservation feature of mergerfs, since it simulates all the files being dropped in the same directory.
I tested it using the scenario of storing 4GB files into drives with sizes (1, 4, 4, 2)TB, until they’re full. The key thing I was looking for in these plots is the separation of the lines. In many strategies the orange and green, and red and blue, lines follow almost the same trajectory, meaning that files are being alternatively assigned between the two during some periods, which would manifest as a fragmented TV show.
First
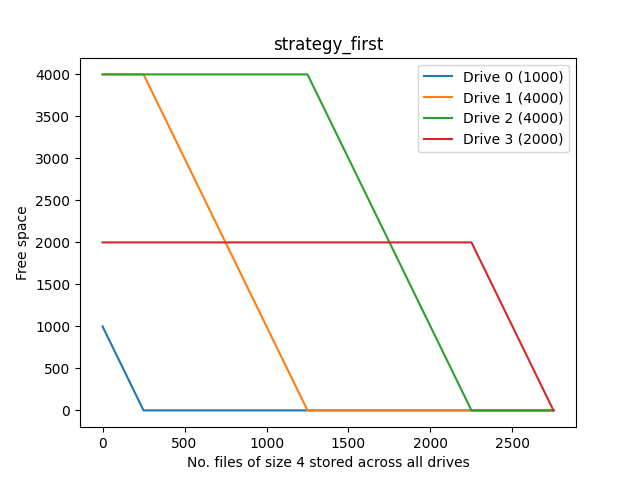
The simplest strategy, and does a decent job, as long as you don’t mind your drives being used somewhat disproportionally.
Least-free space
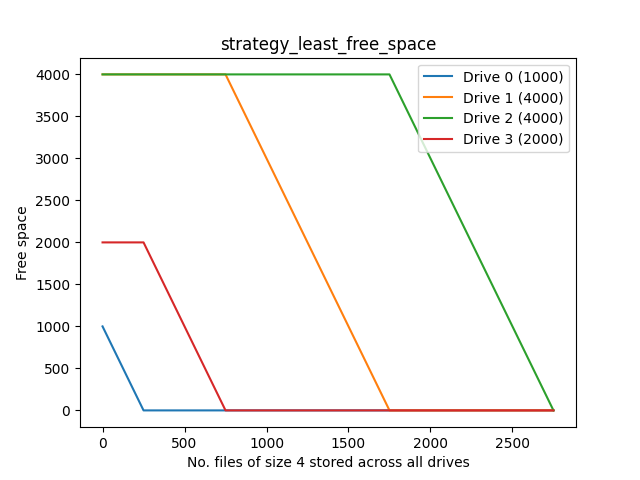
This is what I’m currently using on my setup.
Least-used space
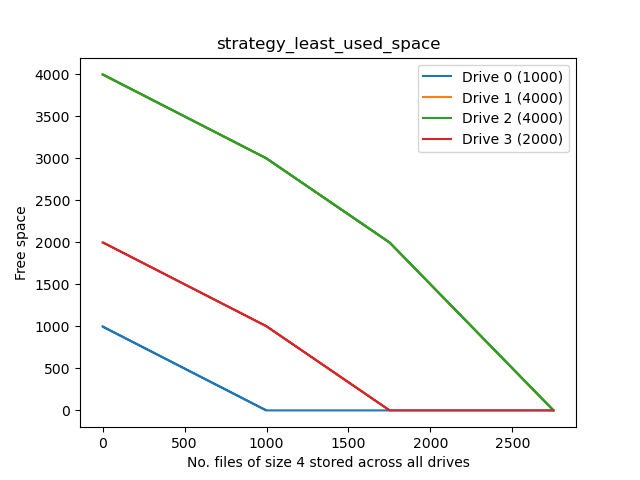
This makes good proportionate use of the drives, but has poor separation of drives 1 and 2.
Most-free space
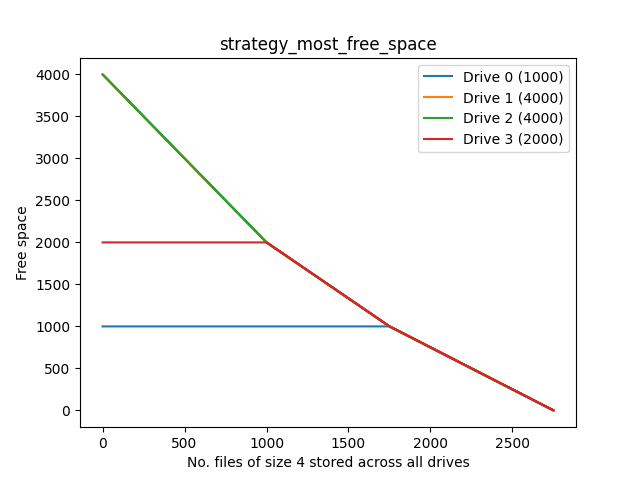
Good proportionate use, but pretty much the worst strategy for colocation.
High-water
This is an Unraid-specific strategy. Quoting from the UI
High-water Choose the lowest numbered disk with free space still above the current high water mark. The high water mark is initialized with the size of the largest data disk divided by 2. If no disk has free space above the current high water mark, divide the high water mark by 2 and choose again.
The goal of High-water is to write as much data as possible to each disk (in order to minimize how often disks need to be spun up), while at the same time, try to keep the same amount of free space on each disk (in order to distribute data evenly across the array).
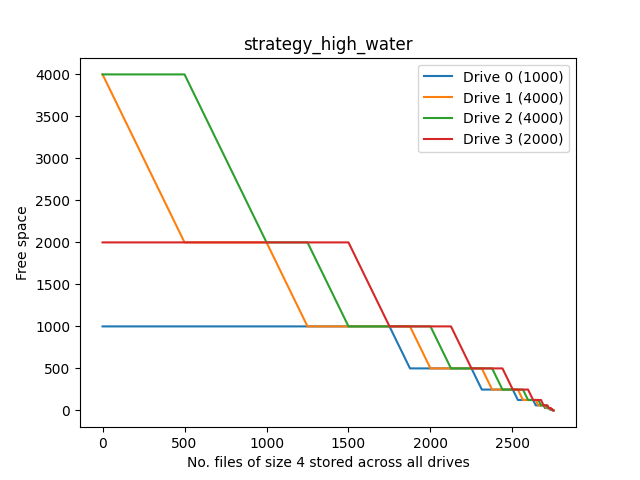
This appears to fulfill its stated goal, making approximately equal use of drives and having good separation of lines. I’d probably use this if I were on Unraid.
Random
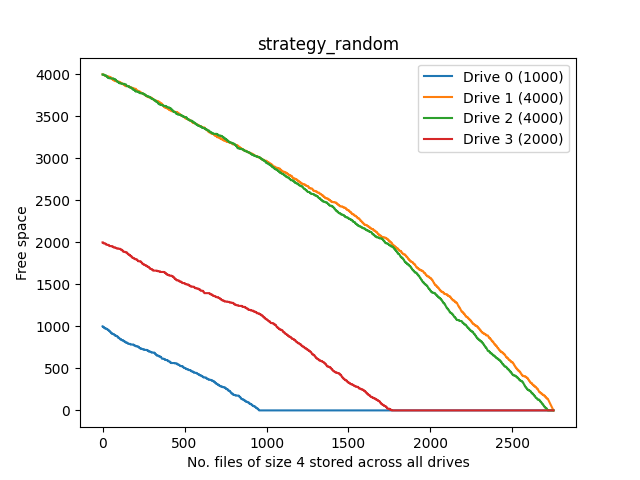
Basically a non-deterministic version of LUS.
Percentage-Free Random Distribution
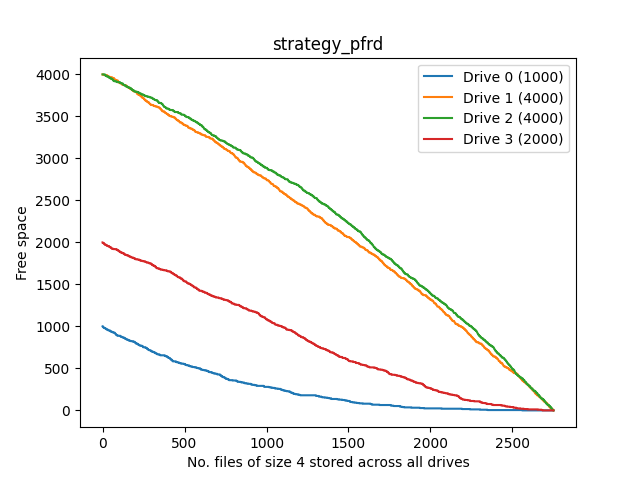
An interesting strategy, but not good for my use case.
Conclusion
So in short, I would recommend
- If you’re on Unraid just use high-water tbh. I think it’s the default too
- If you want colocation, first off make use of the features like maximum split or path preservation that I described earlier, then use LFS or first
- If you want equal usage of drives (to reduce fragmentation), use LUS